当人工智能(AI)从模型训练阶段迈向大规模应用,产业瓶颈发生了根本性转移。2023年,Sequoia的David Cahn提出了悬在AI建设之上的“2000亿美元问题”:每年投入的GPU资本支出,需要产生约2000亿美元的收入才能收回成本,但当时存在巨大的收入缺口。2024年,随着超大规模厂商资本支出膨胀,这一问题升级为“6000亿美元问题”。看空者担忧过度建设将导致供给过剩。
然而,答案并未出现在训练侧,而是出现在推理(inference)侧。市场在过去几周才开始将这一转变计入定价。标志性事件是芯片公司Cerebras的首次公开募股(IPO)获得20倍超额认购,其备受关注的核心能力正是让推理极快的芯片架构,而非训练。与此同时,英伟达(Nvidia)在最新财报中围绕“服务token”重组了披露口径,明确将边缘计算(Edge Computing)提升为与数据中心并列的“第二平台”,这被视为对推理瓶颈的官方确认。

推理与训练的本质区别在于经济模型。训练是一次性的资本支出,而推理是随着每一次AI交互(如Claude回答问题、智能体执行任务)发生的经常性运营成本。摩根大通(J.P. Morgan)估算,推理市场规模可达训练的10到50倍。当AI进入智能体(agentic)时代,机器开始执行由其他机器下达的任务,推理需求将呈现复利式增长,不再仅受用户数限制。
AI应用依赖于一个从芯片制造到API端点的多层算力栈:硅层(英伟达等)、裸金属层(CoreWeave等)、虚拟化层、部署层、模型API层和应用层。大多数公司只专注于其中一层。
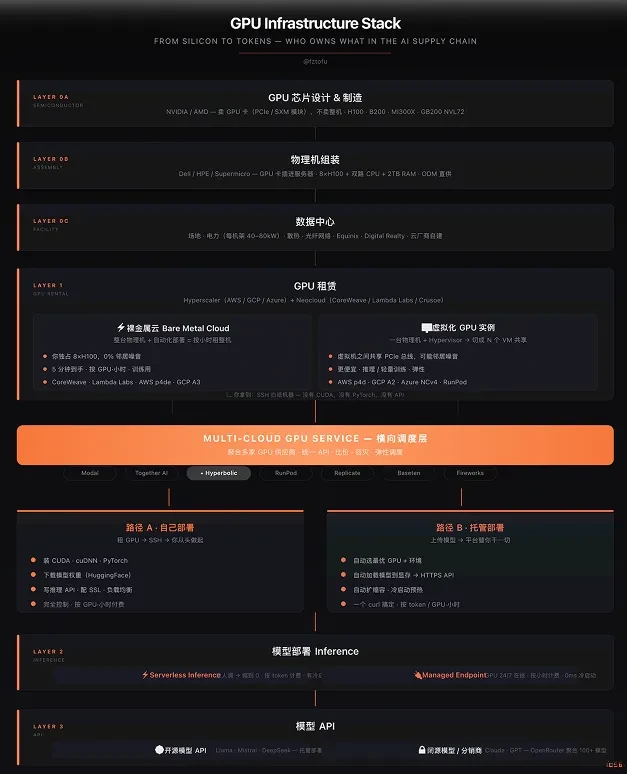
Hyperbolic:横跨三层的聚合者
在众多玩家中,Hyperbolic是唯一同时横跨GPU租赁、部署和模型API三层的公司。该公司于2025年6月推出按需GPU市场,自身不持有任何GPU,而是聚合来自CoreWeave、Lambda Labs、Nebius等数十家云服务商和数据中心的碎片化算力供给,形成一个标准化的统一资源池。
其核心护城河在于“多云聚合”能力。通过坐在供给方与消费方之间,Hyperbolic能够获取实时的GPU价格与供需数据,从而将工作负载智能路由到最便宜、可用的GPU上。随着接入的云越多,其市场流动性越深,数据优势越明显。长期愿景是利用这些数据建模GPU价格曲线,并可能通过自有资本平滑供需,扮演物理算力的做市商角色。
Venice:应用层的隐私推理服务
作为推理经济在应用层的体现,Venice提供了一个隐私优先的推理API和订阅服务。它将用户请求路由到约75个模型(约三分之二为开源或自托管模型),其卖点在于承诺不留存用户数据、不用于训练、并提供匿名化或机密计算环境。
Venice自身不持有重要算力,其成本主要来自向下游租用推理算力和向闭源模型厂商支付的费用。因此,其商业模式实质是在商品化的推理算力之上,包装一层“隐私”溢价进行销售。其经济性高度受制于底层算力的采购成本。
Venice与Hyperbolic形成鲜明对照:如果说Venice是直接面向消费者的“加油站”,那么Hyperbolic就是为其和所有类似应用供应标准化燃料的“炼油厂”和“物流网络”。随着推理需求激增,价值不仅流向消耗算力的应用,更会流向聚合并优化算力配置的中间层。
结论:价值向聚合层沉淀
推理成为稀缺资源,正在重塑AI算力价值链。Anthropic为保障推理产能接管大型数据中心、并对智能体使用进行独立计费,印证了需求的真实性与紧迫性。智能体AI和物理AI的兴起,将进一步放大推理需求。
这也为“6000亿美元问题”提供了新的解答思路。未来的过剩可能不是需求危机,而是轻资产聚合者的机遇。当GPU供给碎片化且价格承压时,能够以最低成本高效匹配工作负载与算力的平台,将捕获最大价值。最终胜出的可能不是拥有最多GPU的公司,而是能告诉你在哪里、以何种价格获得所需算力,并完成最优路由的公司。Hyperbolic正在构建的,正是这样一个推理时代的算力聚合层。












